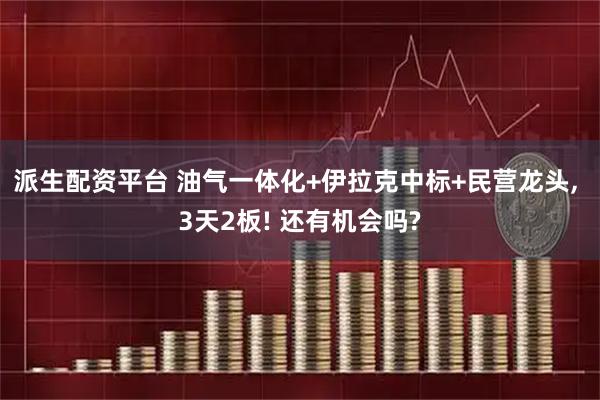
马斯克的公司xAI囤积了大量GPU,但实际利用率却很低。据The Information和Business Insider报道,xAI拥有约50万张英伟达GPU,但实际有效训练算力仅为11%。这一数字来自xAI总裁Michael Nicolls的一份内部备忘录,他形容这个数字“低得尴尬”。
尽管xAI官网宣称Colossus集群已扩展到20万张GPU,并计划最终达到100万张,但实际利用率远低于预期。Nicolls设定了一个目标,希望在未来几个月内将利用率提升至50%。

11%的有效训练算力并不意味着89%的GPU处于闲置状态。实际上,这11%对应的是MFU(模型浮点运算利用率),它衡量的是实际观测到的FLOPS与理论峰值FLOPS之间的比率。换句话说,它关注的是硬件在训练过程中真正转化为有效训练吞吐的部分。

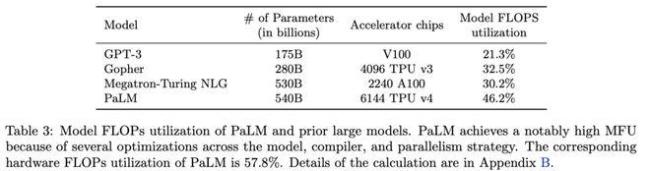
从工程角度来看,低MFU意味着大量电力和硬件时间被浪费在通信、等待、数据搬运和重计算等环节上。相比之下,生产级LLM训练的MFU通常在35%到45%之间。谷歌PaLM论文中也提到,英伟达的Megatron-LM在H100集群上的MFU最高可达47%,即使在强扩展到4608张H100时,MFU也能保持在42%左右。
低MFU的原因多种多样,包括显存压力、单卡batch太小、过度的激活重计算以及跨GPU通信开销等。这些问题不仅影响xAI,也是整个行业的普遍问题。一些研究员为了提高MFU数字,会反复重跑训练实验,以避免被老板批评或GPU被调走。

尽管xAI在硬件部署方面表现出色,但其低MFU表明问题出在更上层的训练栈、并行策略和模型工程上。与此同时,xAI开始将其部分GPU租给编程创业公司Cursor,后者计划使用数万张xAI的GPU来训练其最新编程模型Composer 2.5。这可能成为xAI摊薄基础设施成本的一种选择。

此外,xAI基础设施团队近期发生人事变动,原负责人离职,新团队接管了物理和算力基础设施。这些变化表明,xAI正在调整其业务模式,从自训转向部分算力外部化。虽然xAI官方尚未正面回应11%的MFU数字,但速度扩张带来的复杂度和运维挑战不容忽视。AI竞赛的KPI正在从硬件囤积转向工程师能力和训练栈优化。
国内股票配资提示:文章来自网络,不代表本站观点。